![[NetBSD Logo]](/tnf/resource/NetBSD-headerlogo.png)
GSoC 2018 Reports: Kernel Address Sanitizer, Part 3
Prepared by Siddharth Muralee(R3x) as a part of Google Summer of Code'18.
This is the third and final report of the Kernel Address Sanitizer(KASan) project that I have been doing as a part of Google Summer of Code (GSoC) ‘18 with the NetBSD.
You can refer the first and second reports here :
Sanitizers are tools which are used to detect various errors in programs. They are pretty commonly used as aides to fuzzers. The aim of the project was to build the NetBSD kernel with Kernel Address Sanitizer. This would allow us to find memory bugs in the NetBSD kernel that otherwise would be pretty hard to detect.
Design and principle of KASan
KASan maintains a shadow buffer which is 1/8th the size of the total accessible kernel memory. Each byte of kernel memory is mapped to a bit of shadow memory. Every byte of memory that is allocated and freed is noted in the shadow buffers with the help of the kernel memory allocators.
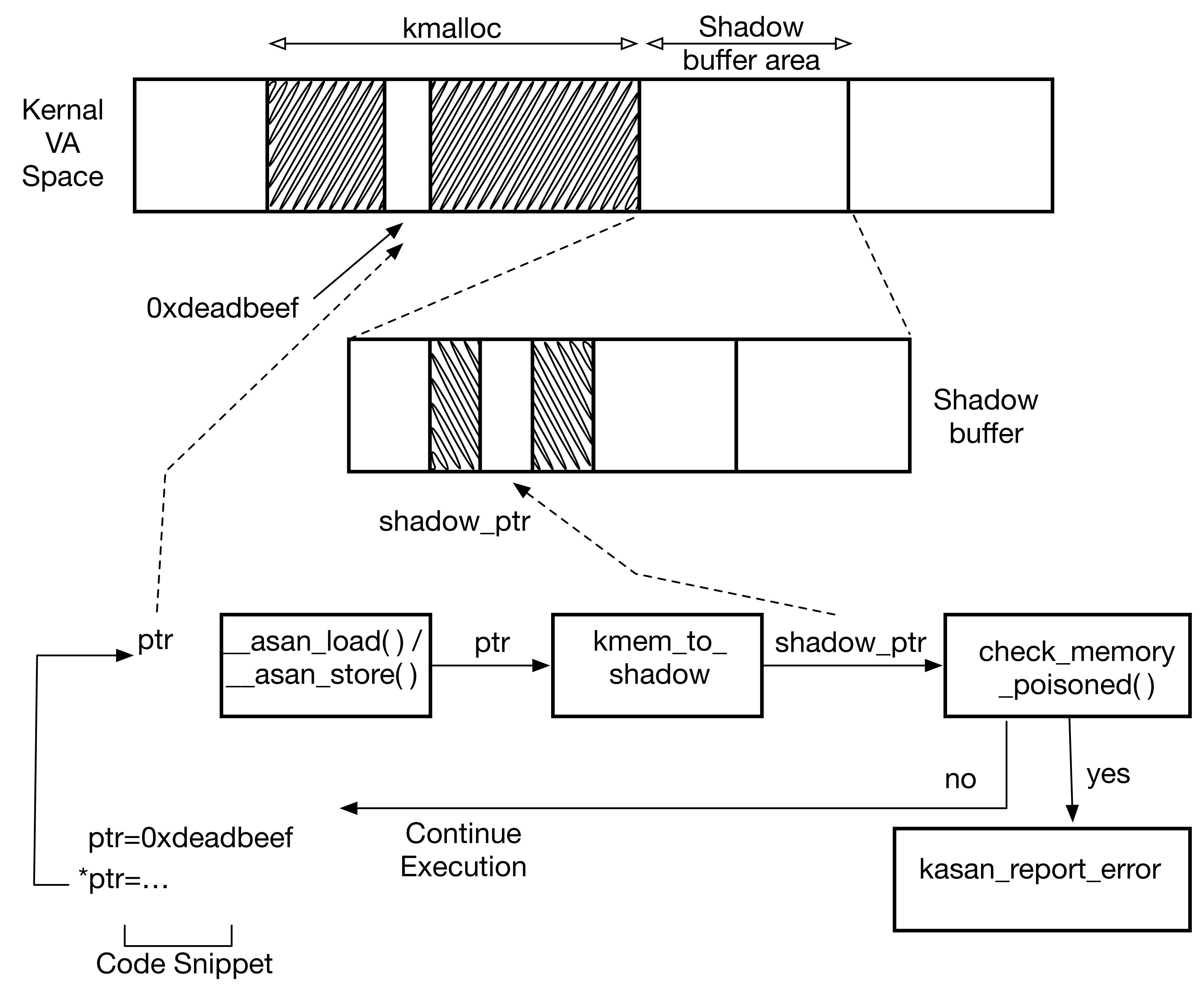
The above diagram shows how a piece of kernel code gets instrumented by the compiler and the checks that it undergoes.
Kasan Initialisation
During kernel boot the shadow memory needs to be initialised. This is done after the pmap(9) and the uvm(9) systems have been bootstrapped.Linux Initialisation model
Linux initialises the shadow buffer in two step method.
Kasan_early_init - Function called in main function of the kernel before the MMU is set up.- Initialises a physical zero page.
- maps the entire top level of the shadow region to a physical zero page.
- The earlier mapping of the shadow region is cleared.
- Allocation of the shadow buffer takes place
- Shadow offsets of regions of kernel memory that are not backed up by actual physical memory are mapped to a single zero page.
- This is done by traversing into the page table and modifying it to point to the zero page.
- Shadow offsets corresponding to the regions of kernel memory that are backed up by actual physical memory are populated with pages allocated from the same NUMA node
- This is done by traversing into the page table and allocating memory from the same NUMA node as the original memory by using early alloc.
- Shadow offsets of regions of kernel memory that are not backed up by actual physical memory are mapped to a single zero page.
- The modifications made to the page table are updated.
Our approach
We decided not to go for a approach which involves updating/modifying the page tables directly. The major reasons for this were
- Modifying the page tables increased the code size by a lot and created a lot of unnecessary complications.
- A lot of the linux code was architecture dependent - implementing the kernel sanitizer for an another architecture would mean reimplementing a lot of the code.
- A lot of this page table modification part was already handled by the low level memory allocators for the kernel. This meant we are rewriting a part of the code.
Hence we decided to move to use a higher level allocator for the allocation purpose and after some analysis decided to use uvm_km_alloc.
- This helped in reducing the code size from around 600 - 700 lines to around 50.
- We didn’t have to go through the pain of writing code to traverse through page tables and allocate pages.
- We feel this code can be reused for multiple architectures mostly by only changing a couple of offsets.
We identified the following memory regions to be backed by actual physical memory immediately after uvm bootstrap.
- Cpu Entry Area - Area containing early entry/exit code, entry stacks and per cpu information.
- Kernel Text Section - Memory with prebuilt kernel executable code
Since NetBSD support for NUMA (Non Uniform Memory Access) isn't available yet. We just allocate them normally.
The following regions were mapped to a single zero-page since they are not backed by actual physical memory at that point.
- Userland - user land doesn't exist at this point of kernel boot and hence isn't backed by physical memory.
- Kernel Heap - The entire kernel memory is basically unmapped at this point (pmap_bootstrap does have an small memory region - which we are avoiding for now)
- Module Map - The kernel module map doesn't have any modules loaded at this point.
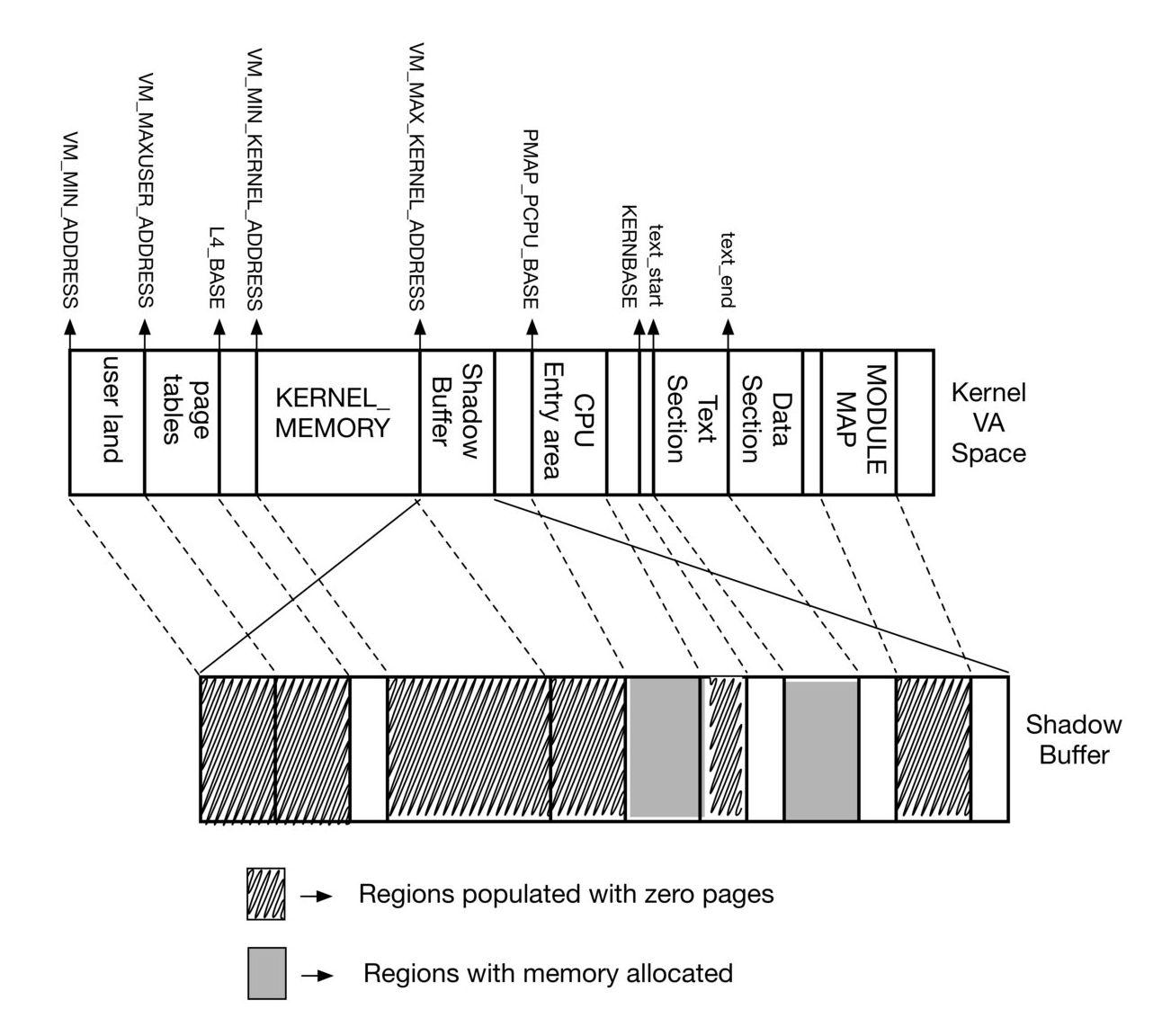
The above diagram shows the mapping of different memory ranges of the NetBSD kernel Virtual Address space and how they are mapped in the Shadow Memory.
You can find the implementation in the file kern_asan_init.c in my Github fork of NetBSD.
This part was time consuming since I had to read through a lot of Linux code, documentation, get a better idea of the Linux memory structure and finally search and figure about similar
Integrating KASan functions with the Allocators
All the memoryallocators(9) would have to be modified so that every allocation and freeing of memory is updated in the shadow memory, so that the checks that the compiler inserts in the code during compile time works properly.
Linux method
Linux has 3 main allocators - slab, slub and slob. Linux had a option to compile the kernel with only a single allocator and hence kasan was meant to work with a kernel that was compiled for using only the slub allocator.
The slub allocator is a object cache based allocator which exported only a short but powerful api of functions namely:
- kmem_cache_create - create an cache
- kmem_cache_reap - clears all slabs in a cache (When memory is tight)
- kmem_cache_shrink - deletes freed objects
- kmem_cache_alloc - allocates an object from a cache
- kmem_cache_free - frees an object from a cache
- kmem_cache_destroy - destroys all objects
- kmalloc - allocates a block of memory of given size from the cache
- kfree - frees memory allocated with kmalloc
All of the functions have a corresponding kasan function inside them to update the shadow buffer. This functions are dummy functions unless the kernel is compiled with KASAN.
Our Approach
NetBSD has four memory allocators and there is no way to build the kernel with just one allocator. Hence, the obvious solution is to instrument all the allocators.
So we had four targets to approach :
- Kmem allocator - General purpose kernel allocator
- Pool allocator - Fixed size allocator
- Pool cache allocator - Cache based fixed size allocator
- Uvm allocator - Low level memory allocator
Pool Cache Allocator
We decided to work on the pool cache allocator first since it was the only allocator which was pretty similar to the slab allocator in linux. We identified potential functions in the pool cache allocator which was similar to the API of the slab allocator.
The functions in pool_cache API which we instrumented with KASan functions.
- pool_cache _init - Allocates and initialises a new cache and returns it (Similar to kmem_cache_create)
- pool_cache_get_paddr - Get an object from the cache that was supplied as the argument. (Similar to kmem_cache_alloc)
- pool_cache_get - Wrapper function around pool_cache_get_paddr and hence skipped.
- pool_cache_put_paddr - Free an object and put it back in the cache. (Similar to kmem_cache_free)
- pool_cache_put - Wrapper function around pool_cache_put_paddr and hence skipped.
- pool_cache_destroy - Destroy and free all objects in the cache (Similar to kmem_cache_destroy)
We noticed that the functions which were responsible for clearing all the unused objects from a cache during shortage of memory were a part of the pagedeamon.
Kmem Allocator
The second target was the kmem allocator since during our initial analysis we found that most of the kmem functions relied on the pool_cache allocator functions initially. This was useful since we could use the same functions in the pool_cache allocator.
Pool Allocator and UVM Allocator
Unfortunately, we didn't get enough time to research and integrate the Kernel Address Sanitizer with the Pool and UVM allocators. I will resume work on it shortly.
Future Work
We are getting the Kernel Address Sanitizer closer and closer to work in the context of NetBSD kernel. After finishing the work on allocators there will be a process of bringing it up.
For future work we leave support of quarantine lists to reduce the number of detected false negatives, this means that we will keep a list of recently unmapped memory regions as poisoned without an option to allocate it again. This means that the probability of use-after-free will go down. Quarantine lists might be probably expanded to some kernel specific structs such as LWP (Light-Weight Process -- Thread entity) or Process ones, as these ones are allocated once and reused between the process of freeing one and allocating a new one.
From other items on the road map we keep handling of memory hotplugging, ATF regression tests, researching dynamic configuration options through sysctl(3) and last but not least getting the final implementation as clean room, unclobbered from potential licensing issues.
Conclusion
Even though officially the GSoC' 18 coding period is over, I definitely look forward keep contributing to this project and NetBSD foundation. I have had an amazing summer working with the NetBSD Foundation and Google. I will be presenting a talk about this at EuroBSDCon '18 at Romania with Kamil Rytarowski.
This summer has had me digging a lot into code from both Linux and NetBSD covering various fields such as the Memory Management System, Booting process and Compilation process. I can definitely say that I have a much better understanding of how Operating Systems work.
I would like to thank my mentor, Kamil Rytarowski for his constant support and patient guidance. A huge thanks to the NetBSD community who have been supportive and have pitched in to help whenever I have had trouble. Finally, A huge thanks for Google for their amazing initiative which provided me this opportunity.
[0 comments]