![[NetBSD Logo]](/tnf/resource/NetBSD-headerlogo.png)
The strongest KASLR, ever?
latest developments in the Kernel ASLR district
Initial design
As I said in the previous episode, I added in October a Kernel ASLR implementation in NetBSD for 64bit x86 CPUs. This implementation would randomize the location of the kernel in virtual memory as one block: a random VA would be chosen, and the kernel ELF sections would be mapped contiguously starting from there.
This design had several drawbacks: one leak, or one successful cache attack, could be enough to reconstruct the layout of the entire kernel and defeat KASLR.
NetBSD’s new KASLR design significantly improves this situation.
New design
In the new design, each kernel ELF section is randomized independently. That is to say, the base addresses of .text, .rodata, .data and .bss are not correlated. KASLR is already at this stage more difficult to defeat, since you would need a leak or cache attack on each of the kernel sections in order to reconstruct the in-memory kernel layout.
Then, starting from there, several techniques are used to strengthen the implementation even more.
Sub-blocks
The kernel ELF sections are themselves split in sub-blocks of approximately 1MB. The kernel therefore goes from having:
{ .text .rodata .data .bss }
to having
{ .text .text.0 .text.1 ... .text.i .rodata .rodata.0 ... .rodata.j ... .data ...etc }
As of today, this produces a kernel with ~33 sections, each of which is
mapped at a random address and in a random order.
This implies that there can be dozens of .text segments. Therefore, even if you are able to conduct a cache attack and determine that a given range of memory is mapped as executable, you don’t know which sub-block of .text it is. If you manage to obtain a kernel pointer via a leak, you can at most guess the address of the section it finds itself in, but you don’t know the layout of the remaining 32 sections. In other words, defeating this KASLR implementation is much more complicated than in the initial design.
Higher entropy
Each section is put in a 2MB-sized physical memory chunk. Given that the sections are 1MB in size, this leaves half of the 2MB chunk unused. Once in control, the prekern shifts the section within the chunk using a random offset, aligned to the ELF alignment constraint. This offset has a maximum value of 1MB, so that once shifted the section still resides in its initial 2MB chunk:

Fig. A: Physical memory, a random offset has been added.
The prekern then maps these 2MB physical chunks at random virtual addresses; but addresses aligned to 2MB. For example, the two sections in Fig. A will be mapped at two distinct VAs:
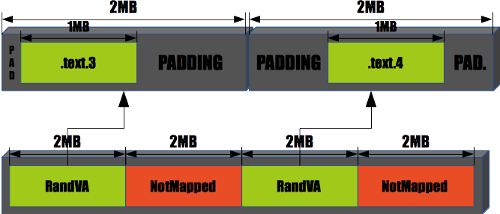
Fig. B: two random, 2MB-aligned ranges of VAs point to the chunks the sections find themselves in.
There is a reason the sections are shifted in memory: it offers higher entropy. If we consider a .text.i section with a 64byte ELF alignment constraint, and give a look at the number of possibilities for the location of the section in memory:
- The prekern shifts the 1MB section in its 2MB chunk, with an offset aligned to 64 bytes. So there are (2MB-1MB)/(64B)=214 possibilities for the offset.
- Then, the prekern uses a 2MB-sized 2MB-aligned range of VA, chosen in a 2GB window. So there are (2GB-2MB)/(2MB)=210-1 possibilities for the VA.
Therefore, there are 214x(210-1)≈224 possible locations for the section. As a comparison with other systems:
| OS | # of possibilities |
|---|---|
| Linux | |
| MacOS | |
| Windows | |
| NetBSD |
Fig. C: comparison of entropies. Note that the other KASLR implementations do not split the kernel sections in sub-blocks.
Of course, we are talking about one .text.i section here; the sections that will be mapped afterwards will have fewer location possibilities because some slots will be already occupied. However, this does not alter the fact that the resulting entropy is still higher than that of the other implementations. Note also that several sections have an alignment constraint smaller than 64 bytes, and that in such cases the entropy is even higher.
Large pages
There is also a reason we chose to use 2MB-aligned 2MB-sized ranges of VAs: when the kernel is in control and initializes itself, it can now use large pages to map the physical 2MB chunks. This greatly improves memory access performance at the CPU level.
Countermeasures against TLB cache attacks
With the memory shift explained above, randomness is therefore enforced at both the physical and virtual levels: the address of the first page of a section does not equal the address of the section itself anymore.
It has, as a side effect, an interesting property: it can mostly mitigate TLB cache attacks. Such attacks operate at the virtual-page level; they will allow you to know that a given large page is mapped as executable, but you don’t know where exactly within that page the section actually begins.
Strong?
This KASLR implementation, which splits the kernel in dozens of sub-blocks, randomizes them independently, while at the same time allowing for higher entropy in a way that offers large page support and some countermeasures against TLB cache attacks, appears to be the most advanced KASLR implementation available publicly as of today.
Feel free to prove me wrong, I would be happy to know!
WIP
Even if it is in a functional state, this implementation is still a work in progress, and some of the issues mentioned in the previous blog post haven't been addressed yet. But feel free to test it and report any issue you encounter. Instructions on how to use this implementation can still be found in the previous blog post, and haven’t changed since.
See you in the next episode!
Posted by Petr Topiarz on November 21, 2017 at 11:24 AM UTC #
Posted by Jean-Yves on November 22, 2017 at 08:26 PM UTC #
Posted by Maxime on November 23, 2017 at 08:39 PM UTC #