![[NetBSD Logo]](/tnf/resource/NetBSD-headerlogo.png)
Revolutionizing Kernel Development: Testing With Rump
There are numerous good tools which do an excellent job of testing kernel features and help to catch bugs. The more frequently they are run as part of the regular development cycle, the more bugs they expose before the bugs are shipped to be discovered by end users. However, prior to being able to execute kernel tests configuration is required. Examples of configuration steps include mounting the file system under test, setting up an NFS server, selecting a network interface and configuring an IP address or setting up a test network. This makes taking a kernel test suite into use unnecessarily complicated and reduces the likelihood of all tests being run by any single kernel developer as part of the development process, thereby reducing the number of bugs which are caught early on.
This article explains how rump is the enabling technology for a safe, fast and run-anywhere kernel test suite which requires absolutely no configuration from the person running the tests. It is a logical continuation for the article about automated testing of NetBSD which described the tools used to run the NetBSD test suite periodically. We will look at various kernel tests, such as those related to file systems, IP routing and kernel data structures, and point out the advantages of using rump as compared to conventional testing approaches.
Features of rump
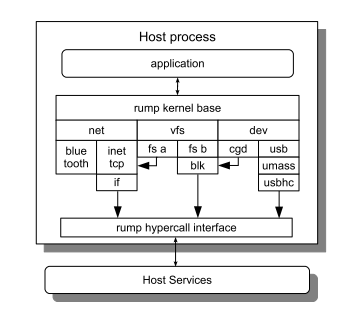 |
While the rump kernel architecture entails more than can be explained in this space, the key thing to know for understanding this article is that rump enables running a fully virtual kernel in a userspace process. In a sense it is similar to usermode operating systems, but with the two critical distinctions that the kernel is highly componentized and there is no separate userland. This means:
- very fast bootstrap times (in the order of 0.01s)
- allows writing tests as self-contained packages which include all configuration steps necessary for the test
- makes result gathering automatic and easy even in the case where the test leads to a kernel panic
- testing uses only the minimum resources necessary
Virtual
Rump provides a virtual instance of the kernel. This means that
it is both in a separate namespace from the host and that if the
test requires it, an arbitrary number of kernels be spawned by
calling fork().
First, let us identify what an isolated virtual namespace means: for example memory counters, received network packet counters, sysctl switch values, and buffer cache size limits are private to the rump kernel. The same privacy applies to other system resources such as the file system namespace, IP ports and driver instance identifiers (e.g. raid2). This gives the test author the freedom to use and modify resources without affecting the host and also gives confidence that irrelevant events caused by other processes running on the same system do not lead to incorrect results. This means that tests are also protected from each other: it is possible to run multiple tests in parallel without risk of them affecting each other and causing hard-to-duplicate test failures.
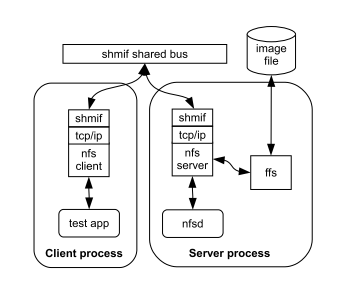 |
Second, virtualization can be used to start multiple instances of a kernel. This is important in cases like networking, where testing complex routing schemes requires numerous hosts to be available. Another example is testing NFS by providing the NFS server and client in separate kernels. This case is illustrated Figure 2. The network interface depicted in the figure deserves special mention: as opposed to the normal approach of using the host's Ethernet tap driver and bridges for creating virtual networks, rump tests executed within one host use a special interface with a memory mapped file as the interprocess bus. This means that as long as tests are executed in a private directory (and they are), networking is fully private as opposed to depending on a shared host resource.
As an example we briefly discuss the test for NetBSD PR kern/43548. The bug, in
essence, is a kernel panic in the IP forwarding routine when
sending an ICMP TTL exceeded. In a virtual kernel the value of
net.inet.icmp.returndatabytes necessary to tickle the
bug can be set without disturbing the network traffic on the host.
The second advantage of rump virtualization in the test is fast
bootstrapping of two kernels: one to send a packet and one to act
as the router for the packet to catch and process it in
ip_forward(), thus triggering the bug.
Note that for networking other solutions for lightweight virtualization exist, such as Solaris Zones. However, they make a poor candidates for the above test, since they use the same kernel as the host and are not suitable in tests which aim to cause a kernel crash. Acceptable alternatives would be fully virtual OSs like ones running on top of Xen or QEMU, or a Usermode OS, but those have very high setup and per-test bootstrap costs.
Crashproof
The rump kernel runs entirely as part of a normal userspace process. This means that no bug in the kernel under test can bring the test host down. One of the goals of the NetBSD test suite is to make it easy to run without special setups, and that requires that there is no increased risk of crashing the test host.
However, it is reasonable to desire to test experimental features which are not yet production stable. This not only makes it possible to monitor the progress of the subsystem, but also ensures that no regressions in stability happen due to other changes. For example, LFS (log-structured file system) is considered experimental. While it works, some operations carry a high risk of kernel panic. The NetBSD test suite contains numerous tests for LFS with associated Problem Report (PR) numbers where the test causes a kernel panic or otherwise fails. These tests can also be used as a guideline to repeat and fix LFS problems.
In addition to being able to test experimental kernel features, it is also possible to immediately add and enable a test case for a bug causing a kernel crash. Test suites based on the host kernel require waiting until the bug is fixed to prevent other test suite users from suffering disruptive crashes during test suite execution.
Furthermore, for a limited number of tests the correct outcome is
a kernel panic or reboot. For example, one of the test cases for
the kernel watchdog expects a reboot in case the watchdog is not
tickled within the timeout period. The automated rump test forks
a new virtual kernel and gives a verdict based on the return value
of wait().
Another advantage of being crashproof is fuzzing and fault injection. These two types of tests feed seemingly random input to the unit under test or cause a backend used by the unit under test to fail, respectively. As these tests are designed to exercise error paths where undetected bugs most often lurk, it is not uncommon to see them cause a kernel crash.
Finally, tests for kernel high availability features such as CARP can be executed in an authentic fashion by simply killing off the master and observing if handover to the backup is done according to specification.
Complete
It is normal practice for kernel features to be unit tested in userspace
by compiling the source module(s) with a special testing
#define. This straightforward method has two problems.
First, it requires working towards this target already when writing
the code and can be difficult to achieve as an afterthought. Second,
it is limited by the inherent problems of just unit testing: only
a limited fraction of the full picture is exercised and the test
may miss subtle interactions between kernel components.
Rump, on the other hand, provides a complete software stack from the system call entry point to the kernel feature under test. Kernel code runs in a rump kernel without the code being written in a specific way. On i386 and amd64 it is even possible to use standard binary kernel modules as drivers in a rump kernel -- though, most of the time kernel module binaries lack debugging information and are not useful in case a problem is discovered.
Debugging
If testing uncovers a problem, figuring out what went wrong is the prerequisite for fixing the problem. We look at how rump helps with debugging the problem. For discussion, we divide issues into three broad categories:
- system call returns an incorrect value
- system call causes a deterministic kernel crash
- a set of timing related events cause a kernel crash
1: An all too common error value returned from a system call
is EINVAL. Sometimes the location of the error is
extremely difficult to determine by educated guesses. For example,
a problem with mounting small FFS file systems was reported
recently. The easy way to figure out where the error was coming
from was to single-step the mount system call into the rump kernel
to discover the source of the error.
2: Deterministic kernel crashes are nice to debug since they can be reliably repeated. In the normal scenario the choices are to debug the situation directly with the in-kernel debugger, attach an external debugger, or write a kernel core image to swap space, reboot, and examine the status post-mortem. The first option provides instant debugging, but works on a machine code level instead of the source level. The second option requires additional setup, and the third option introduces a delay in between the crash and being able to debug it. In contrast, a rump kernel panic is an application level core dump, and it can be debugged immediately with a source level debugger.
3: Timing problems are generally the hardest problems to
debug, since they depend on a seemingly random order of events
which in the best case happens frequently and in the worst case
extremely rarely. Usually the only way is to make educated guesses
and put print calls into suitable places to gather more data
and narrow down the suspects. However, the problem with calling
the kernel print routine is that it runs inside the kernel, takes
locks and generally influences kernel execution. Rump provides a
print routine which executes on the host. It requires no special
setup or parameters, just calling rumpuser_dprintf()
instead of printf(). While the call still takes wall
time, it does not use rump kernel resources and has generally been
found better for tracking down timing problems. This combined with
the fast iteration cycle that rump offers are powerful tools in
debugging failed test cases.
For example, a faulty invariant due to a lockless algorithm in the file descriptor code was discovered as part of unrelated testing, quickly narrowed down, isolated, and fixed. Also, a test which reliably triggers the invariant panic in around 100000 iterations was added to make sure the bug does not resurface. This issue is described in PR kern/43694.
Timing problems are sometimes exposed more readily on a multiprocessor setup where multiple threads enter the same areas of code simultaneously. Since the CPU count provided by rump is virtual, SMP can be simulated on uniprocessor machines. For example, the race condition described in PR kern/36681 triggers on a uniprocessor system when rump is configured to provide two virtual CPUs. As opposed to some other technologies, a rump kernel can use all of the host processors and does not experience expotential slowdown as the number of virtual CPUs increases.
In summary, the advantages provided by rump for the cases mentioned in the beginning of the section are:
- seamless single-stepping into the kernel
- instant source level debugging
- external print routine, quick iteration, virtual SMP
Limitations
Although applicable for a major part of the NetBSD kernel, rump does not support all subsystems. This is by design for reasons which are beyond the scope of this article. The subsystems beyond the reach rump are the virtual memory subsystem (UVM) and the thread scheduler. Even so, it is important not to confuse the lack of the standard VM subsystem with the inability to stress the kernel under resource shortage. As already hinted earlier, a resource shortage such as lack of free memory can be trivially simulated with rump without affecting the test host or the test program.
Hardware testing is another area where tests cannot be fully automated with rump. This is not so much due to rump -- rump does support USB hardware drivers -- but more because of the nature of hardware: the test operator is required to plug in the hardware under test and supply its location to the test.
Conclusions
We presented a revolutionary method for automated kernel testing built upon the unique rump kernel architecture of NetBSD. Rump provides a crashproof and lightweight fully virtual kernel featuring a complete software stack and is second to none for kernel testing.
The result of using rump for kernel testing is a test suite which anyone can safely run anywhere, and which is not limited only to kernel developers with highly specialized knowledge on how to set up the test environment. The author strongly believes that the superior test suite will solidify NetBSD's reputation as the most stable and bug-free operating system.
Further Resources
A standard NetBSD installation contains the test suite in
While some features mentioned in this article are available in the NetBSD 5.0 release, most are present only in the development branch of NetBSD and will be new in NetBSD 6.0 when it is eventually released.
[7 comments]
Posted by PaulC on August 20, 2010 at 07:02 AM UTC #
Posted by Thomas on August 20, 2010 at 09:38 AM UTC #
Posted by Antti Kantee on August 20, 2010 at 02:07 PM UTC #
Posted by Antti Kantee on August 20, 2010 at 02:18 PM UTC #
Posted by Thomas on August 20, 2010 at 08:32 PM UTC #
Posted by Antti Kantee on August 21, 2010 at 12:54 AM UTC #
Posted by moncler jacke on October 08, 2010 at 08:34 AM UTC #