![[NetBSD Logo]](/tnf/resource/NetBSD-headerlogo.png)
Debugging FFS Mount Failures
This report was written by Maciej Grochowski as a part of developing the AFL+KCOV project.
This report is a continuation of my previous work on Fuzzing Filesystems via AFL.
You can find previous posts where I described the fuzzing (part1, part2) or my EuroBSDcon presentation.
In this part, we won't talk too much about fuzzing itself but I want to describe the process of finding root causes of File system issues and my recent work trying to improve this process.
This story begins with a mount issue that I found during my very first run of the AFL, and I presented it during my talk on EuroBSDcon in Lillehammer.
Invisible Mount point
afl-fuzz: /dev/vnd0: opendisk: Device busy That was the first error that I saw on my setup after couple of seconds of AFL run.
I was not sure what exactly was the problem and thought that mount wrapper might cause a problem.
Although after a long troubleshooting session I realized that this might be my first found issue.
To give the reader a better understanding of the problem without digging too deeply into fuzzer setup or mount process.
Let's assume that we have some broken file system image exposed as a block device visible as a /dev/wd1a.
The device can be easily mounted on mount point mnt1, however when we try to unmount it we get an error: error: ls: /mnt1: No such file or directory, and if we try to use raw system call unmount(2) it also end up with the similar error.
However, we can see clearly that the mount point exists with the mount command:
# mount
/dev/wd0a on / type ffs(local)
...
tmpfson /var/shmtype tmpfs(local)
/dev/vnd0 on /mnt1 type ffs(local)
Thust any lstat(2) based command is trying to convince us that no such directory exists.
# ls / | grep mnt
mnt
mnt1
# ls -alh /mnt1
ls: /mnt1: No such file or directory
# stat /mnt1
stat: /mnt1: lstat: No such file or directory
To understand what is happening we need to dig a little bit deeper than with standard bash tools.
First of all mnt1 is a folder created on the root partition at a local filesystem so getdents(2) or dirent(3) should show it as a entry inside dentry structure on the disk.
Raw getdents syscall is great tool for checking directory content because it reads the data from the directory structure on disk.
# ./getdents /
|inode_nr|rec_len|file_type|name_len(name)|
#: 2, 16, IFDIR, 1 (.)
#: 2, 16, IFDIR, 2 (..)
#: 5, 24, IFREG, 6 (.cshrc)
#: 6, 24, IFREG, 8 (.profile)
#: 7, 24, IFREG, 8 (boot.cfg)
#: 3574272, 24, IFDIR, 3 (etc)
...
#: 3872128, 24, IFDIR, 3 (mnt)
#: 5315584, 24, IFDIR, 4 (mnt1)
Getdentries confirms that we have mnt1 as a directory inside the root of our system fs.
But, we cannot execute lstat, unmount or any other system-call that require a path to this file.
A quick look on definitions of these system calls show their structure:
unmount(const char *dir, int flags);
stat(const char *path, struct stat *sb);
lstat(const char *path, struct stat *sb);
open(const char *path, int flags, ...);All of these function take as an argument path to the file, which as we know will endup in vfs lookup.
How about something that uses filedescryptor? Can we even obtain it?
As we saw earlier running open(2) on path also returns EACCES.
Looks like without digging inside VFS lookup we will not be able to understand the issue.
Get Filesystem Root
After some debugging and code walk I found the place that caused error.
VFS during the name resolution needs to check and switch FS in case of embedded mount points.
After the new filesystem is found VFS_ROOT is issued on that particular mount point.
VFS_ROOT is translated in case of FFS to the ufs_root which calls vcache with fixed value equal to the inode number of root inode which is 2 for UFS.
#define UFS_ROOTINO ((ino_t)2) Below listning with the code of ufs_root from ufs/ufs/ufs_vfsops.c.
int
ufs_root(struct mount *mp, struct vnode **vpp)
{
...
if ((error = VFS_VGET(mp, (ino_t)UFS_ROOTINO, &nvp)) != 0)
return (error);By using the debugger, I was able to make sure that the entry with number 2 after hashing does not exist in the vcache.
As a next step, I wanted to check the Root inode on the given filesystem image.
Filesystem debuggers are good tools to do such checks. NetBSD comes with FSDB which is general-purpose filesystem debugger.
Nonetheless, by default FSDB links against fsck_ffs which makes it tied to the FFS.
Filesystem Debugger for the help!
Filesystem debugger is a tool designed to browse on-disk structure and values of particular entries.
It helps in understanding the Filesystems issues by giving particular values that the system reads from the disk.
Unfortunately, current fsdb_ffs is a bit limited in the amount of information that it exposes.
Example output of trying to browse damaged root inode on corrupted FS.
# fsdb -dnF -f ./filesystem.out
** ./filesystem.out (NO WRITE)
superblock mismatches
...
BAD SUPER BLOCK: VALUES IN SUPER BLOCK DISAGREE WITH THOSE IN FIRST ALTERNATE
clean = 0
isappleufs = 0, dirblksiz = 512
Editing file system `./filesystem.out'
Last Mounted on /mnt
current inode 2: unallocated inode
fsdb (inum: 2)> print
command `print
'
current inode 2: unallocated inode
FSDB Plugin: Print Formatted
Fortunately, fsdb_ffs leaves all necessary interfaces to allows accessing this data with small effort.
I implemented a simple plugin that allows browsing all values inside: inodes, superblock and cylinder groups on FFS.
There are still a couple of todos that have to be finished, but the current version allows us to review inodes.
fsdb (inum: 2)> pf inode number=2 format=ufs1
command `pf inode number=2 format=ufs1
'
Disk format ufs1inode 2 block: 512
----------------------------
di_mode: 0x0 di_nlink: 0x0
di_size: 0x0 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x0 di_gen: 0x6c3122e2
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
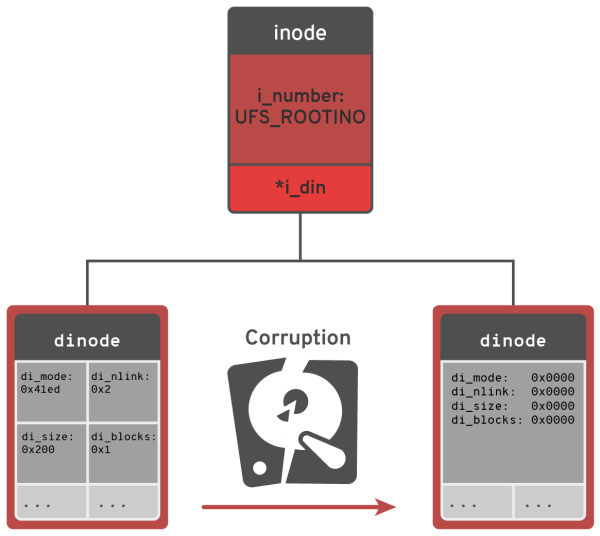
We can see that the Filesystem image got wiped out most of the root inode fields.
For comparison, if we will take a look at root inode from freshly created FS we will see the proper structure.
Based on that we can quickly realize that fields: di_mode, di_nlink, di_size, di_blocks are different and can be the root cause.
Disk format ufs1 inode: 2 block: 512
----------------------------
di_mode: 0x41ed di_nlink: 0x2
di_size: 0x200 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x1 di_gen: 0x68881d2c
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
From FSDB and incore to source code
First we will summarize what we already know:
- unmount fails in namei operation failure due to the corrupted FS
- Filesystem has corrupted root inode
- Corrupted root inode has fields: di_mode, di_nlink, di_size, di_blocks set to zero
Now we can find a place where inodes are loaded from the disk, this function for FFS is ffs_init_vnode(ump, vp, ino);.
This function is called during the loading vnode in vfs layer inside ffs_loadvnode.
Quick walkthrough through ffs_loadvnode expose the usage of the field i_mode:
error = ffs_init_vnode(ump, vp, ino);
if (error)
return error;
ip = VTOI(vp);
if (ip->i_mode == 0) {
ffs_deinit_vnode(ump, vp);
return ENOENT;
}
This seems to be a source of our problem. Whenever we are loading inode from disk to obtain the vnode, we validate if i_mode is non zero.
In our case root inode is wiped out, what results that vnode is dropped and an error returned.
So simply we cannot load any inode with i_mode set to the zero, inode number 2 called root is no different here.
Due to that the VFS_LOADVNODE operation always fails, so lookup does and name resolution will return ENOENT error.
To fix this issue we need a root inode validation on mount step, I created such validation and tested against corrupted filesystem image.
The mount return error, which proved the observation that such validation would help.
Conclusions
The following post is a continuation of the project: "Fuzzing Filesystems with kcov and AFL".
I presented how fuzzed bugs, which do not always show up as system panics, can be analyzed, and what
tools a programmer can use.
Above the investigation described the very first bug that I found by fuzzing mount(2) with Afl+kcov.
During that root cause analysis, I realized the need for better tools for debugging Filesystem related issues.
Because of that reason, I added small functionality pf (print-formatted) into the fsdb(8), to allow walking through the on-disk structures.
The described bug was reported with proposed fix based on validation of the root inode on kern-tech mailing list.
Future work
- Tools: I am still progressing with the fuzzing of mount process, however, I do not only focus on the finding bugs but also on tools that can be used for debugging and also doing regression tests.
I am planning to add better support for browsing blocks on inode into the
fsdb-pf, as well as write functionality that would allow more testing and potential recovery easier. - Fuzzing: In next post, I will show a remote setup of AFL with an example of usage.
- I got a suggestion to take a look at FreeBSD UFS security checks on
mount(2)done by McKusick. I think is worth it to see what else is validated and we can port to NetBSD FFS.
Posted by Arnaiz on November 27, 2019 at 09:52 PM UTC #